What skills are you expected to have as a senior Java developer?
You need at least 4-6 projects under your belt to become a so called "senior" developer. Some achieve it quicker than the others. It is harder to quantify by number of years because some gain real 3-5 year hands-on experience, whilst others repeat the same year 2 to 3 times. Here is the list of skills you need to have accomplished in my view to become a senior Java developer.
Skill #1: Good "software craftsmanship" skills. In other words have good handle on the 16 technical key areas listed below. You should have the ability to ask the right questions (e.g. should I use aspect oriented programming (i.e. AOP) here?, should I favor optimistic or pessimistic locking here? should the method call made within a transactional context?) and solve problems (e.g. memory leaks, thread safety, SQL injection attacks, performance, etc) relating to these 16 technical key areas.
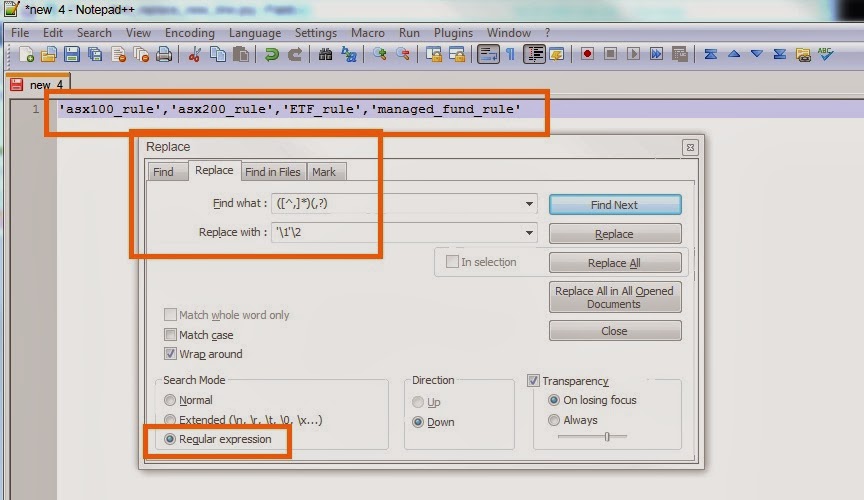
What are these 16 key areas?
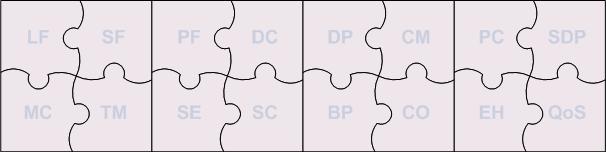
What are these 16 key areas?
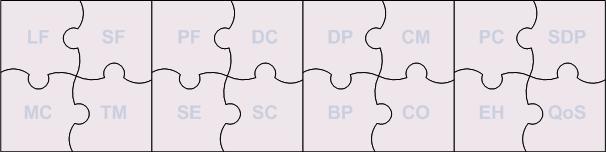
- Language Fundamentals (LF)
- Specification Fundamentals (SF)
- Platform Fundamentals (PF)
- Design Considerations (DC)
- Design Patterns (DP)
- Concurrency Management (CM)
- Performance Considerations (PC)
- Memory/Resource Considerations (MC)
- Transaction Management (TM)
- Security (SE)
- Scalability (SC)
- Best Practices (BP)
- Coding (CO)
- Exception Handling (EH)
- Software Development Processes (SDP)
- Quality of Service (QoS)
Skill #2: Ability to look at things from both business and technical perspective. It is also imperative to have good communication, analytical, interpersonal, and researching skills to transform the business requirements into conceptual design and detailed technical design with pros and cons, risk assessment, tactical vs strategical approach, UML diagrams, ER (Entity Relationship) diagrams, class diagrams and OO concepts.
Transform functional and non functional requirements like logging, auditing, capacity planning, load balancing, instrumentation (to ensure 24 x 7 availability), disaster recovery and archival strategies of data (e.g. regular back ups) to build a robust system that meets the SLAs (Service Level Agreement).
Transform functional and non functional requirements like logging, auditing, capacity planning, load balancing, instrumentation (to ensure 24 x 7 availability), disaster recovery and archival strategies of data (e.g. regular back ups) to build a robust system that meets the SLAs (Service Level Agreement).
Skill #3: Good working experience of conceptual architectures. Only experience will tell what works well in which environment. In other words you need to have the ability to look at the overall system at a 100 feet without delving into its details. Understand the environments (e.g. skill-sets of the developers, business unit structure, tool sets used, existing capabilities, etc ), and the team culture to decide what will work and what will not. Don't just read an article off the internet and think that it can be easily applied to your environment. For example, adopting agile development practices or service oriented architectures has its own challenges and need full co-operation and commitment from the senior management. It will not work in every environment. It requires gradual and progressive changes to get there. Sometimes you need to quickly change tactics based on the challenges you face.
Skill #4: Right soft skills and attitude to thrive in a team environment. Don't wait for things to happen but make things happen by taking initiatives and communicating your thoughts more effectively with the can do attitude and right emotions to work with others as a team.
For example, sometimes the business requirements might not be clear. As a senior developer, you need to have the right soft skills to take initiatives to clarify and document the business requirements. Software development is like fitting all the puzzles (e.g. 16 key areas and non functional requirements) together like a puzzle. It is hard to have all the technical skills under the sun. So, you need to collaboratively work with the multi-disciplinary teams to tap into others' skills get the job done. It is important to learn to handle criticisms and avoid "I know it all" attitude.
For example, sometimes the business requirements might not be clear. As a senior developer, you need to have the right soft skills to take initiatives to clarify and document the business requirements. Software development is like fitting all the puzzles (e.g. 16 key areas and non functional requirements) together like a puzzle. It is hard to have all the technical skills under the sun. So, you need to collaboratively work with the multi-disciplinary teams to tap into others' skills get the job done. It is important to learn to handle criticisms and avoid "I know it all" attitude.
Skill #5: Using the right tools for productivity gains. For example, I have blogged about using Notepad++ and excel to manipulate data and construct complex SQL queries quickly. I have also blogged about many other tools for debugging Java apps, testing RESTful web services, and web applications. Unix is very powerful to automate repetitive tasks.
Skill #6: Taking pride in your work and invest in continuously learning. You will be continuously re-factoring and improving your work. You will know what to look for when reviewing others' code. You will have better diagnostic skills. You will know how to avoid the common pitfalls. You will be motivated to invest more time in your learning and sharing your experience through blogging, helping fellow professionals via industry specif forums, and writing articles. You will be opinionated as to what new features or improvements you would like to be added in the future releases.
As a seasoned developer, you will know how to take a project through the full SDLC activities as doer and facilitator.
Note: I have blogged about some of the 16 key areas and tools for improving productivity. These links can be found on the RHS panel. My book entitled "How to open more doors as a software engineer?" covers all the 16 key areas and many insights in to expanding your horizons as a senior Java developer.
Labels: Java career, Java developer
posted by Unknown at
12/24/2013 12:12:00 PM
|
0 Comments
![]()
![]()